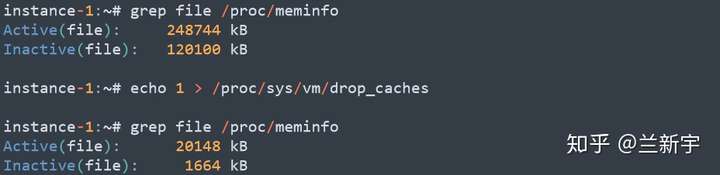
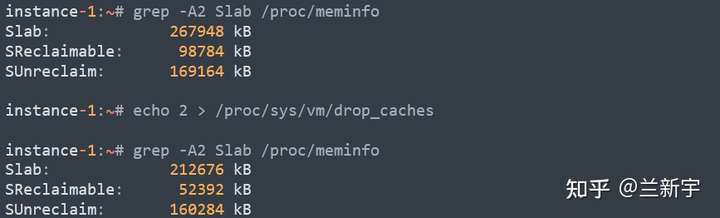
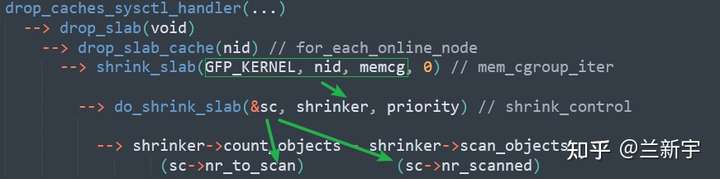
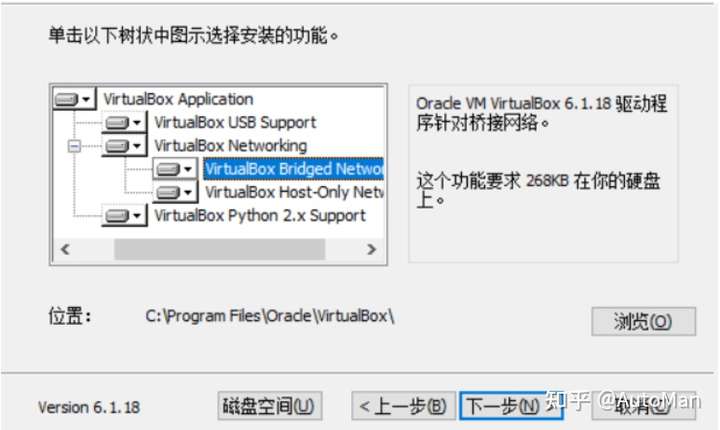
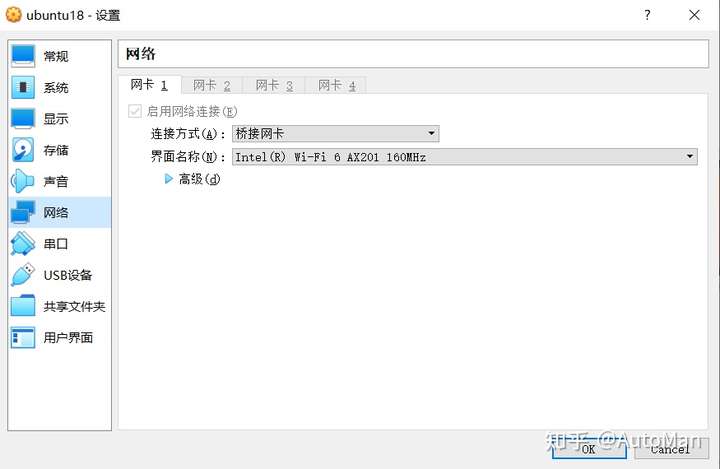
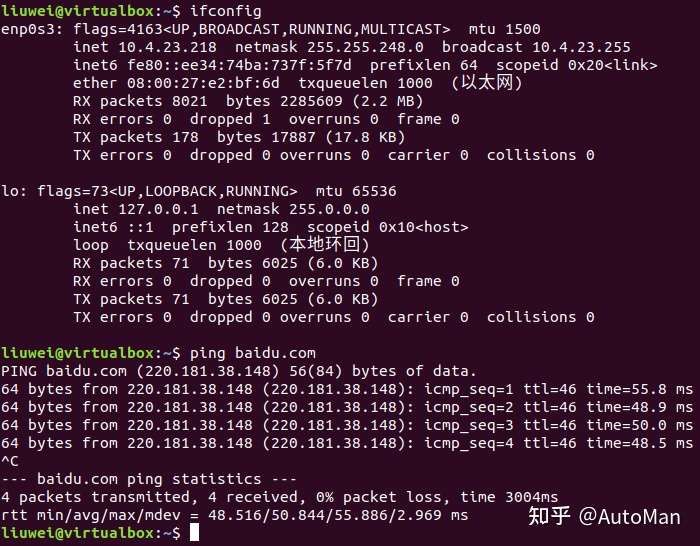
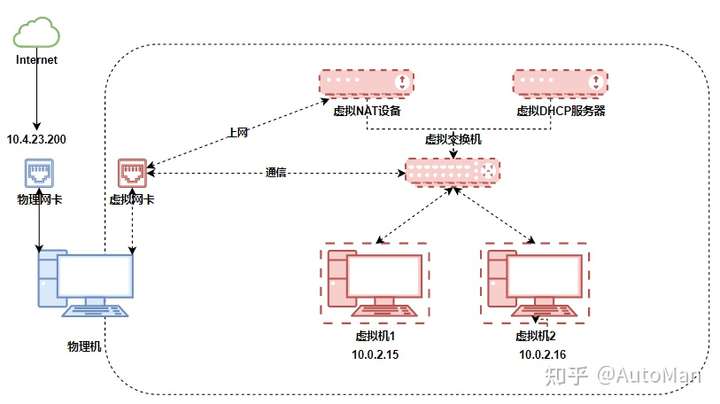
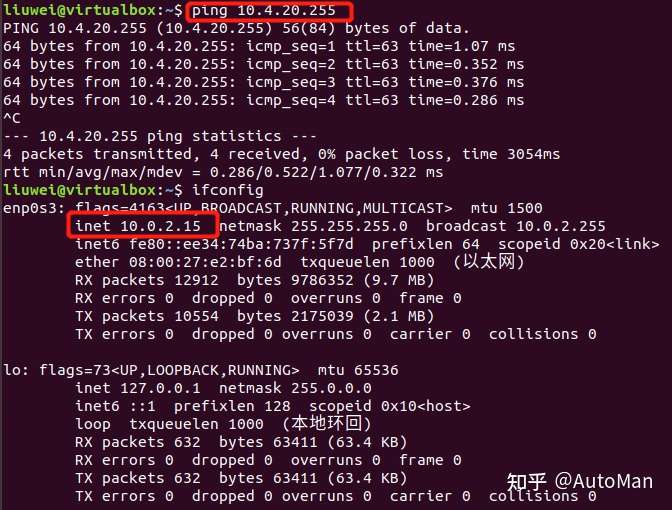
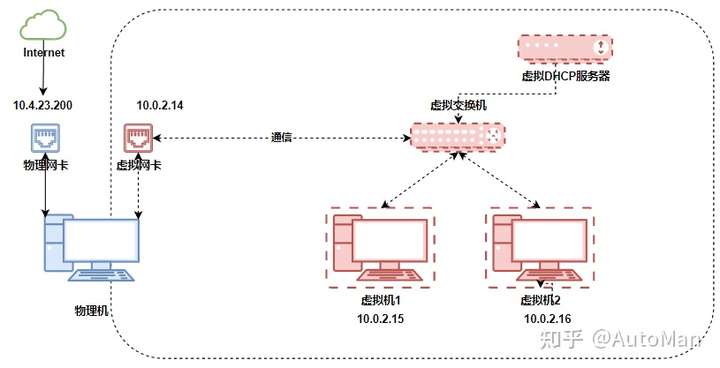
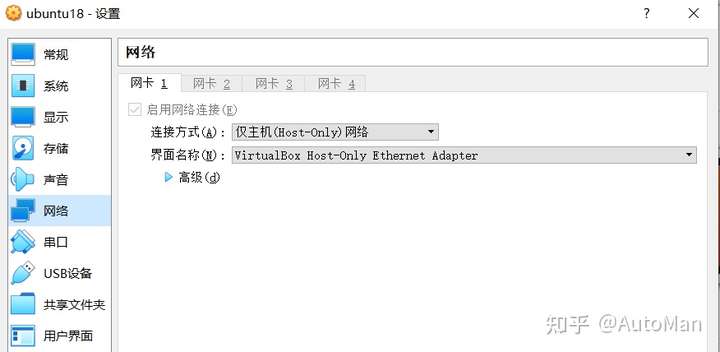
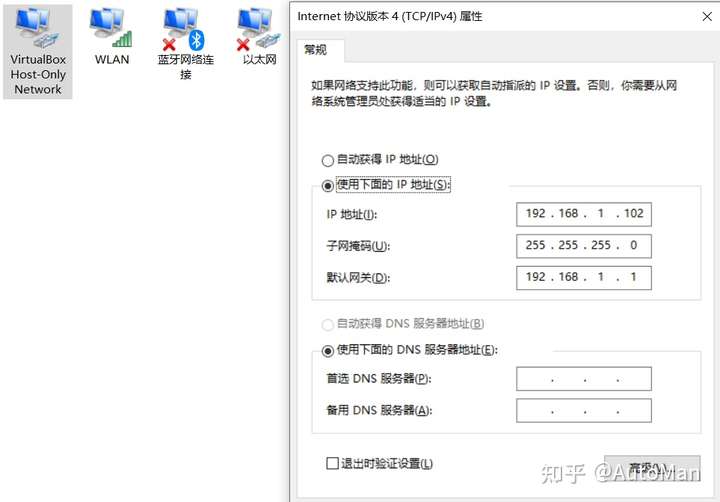
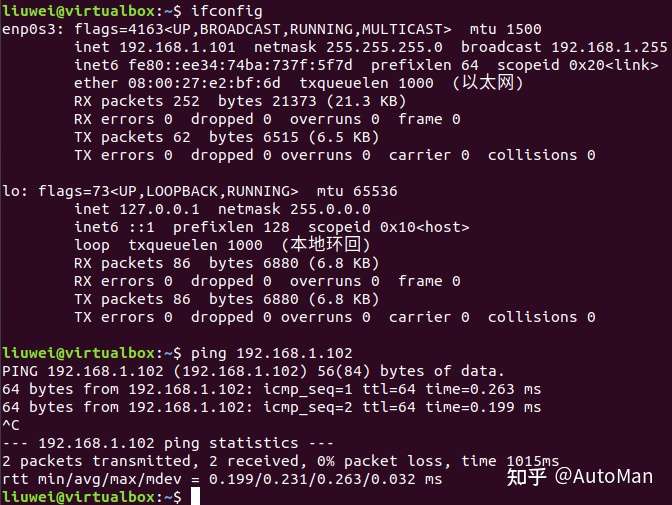
看到一个很好的文章,学习记录一下,原文链接可以在最后找到
在很多人的眼里,C语言和linux常常是分不开的。这其中的原因很多,其中最重要的一部分我认为是linux本身就是C语言的杰出作品。当然,linux操作系统本身对C语言的支持也是相当到位的。作为一个真正的程序员来说,如果没有在linux下面用C语言编写过完整的程序,那么只能说他对C语言本身的理解还相关肤浅,对系统本身的认识也不够到位。作为程序员来说,linux系统为我们提供了很多理想的环境,这其中包括了下面几个方面,
(1)完善的编译环境,包括gcc、as、ld等编译、链接工具
(2)强大的调试环境,主要是gdb工具
(3)丰富的自动编译工具,主要是make工具
(4)多样化的os选择,ubuntu、redflag等等
(5)浩瀚的开源代码库
当然,不管我怎么说,最终朋友们还是应该自己勇敢地跨出前进的第一步。
如果还没有过Linux编程经验的朋友可以首先在自己的pc上面安装一个虚拟机,然后就可以在shell下面编写自己的C语言代码了。
#include <stdio.h>
int main()
{
printf("hello!\n");
return 1;
}
编写完上面的代码后,你需要做的就是两个步骤:
1、输入 gcc hello.c -o hello;
2、输入./hello。
如果一切正常的话,此时你应该会在屏幕上看到一行hello的打印。如果你看到了,那么恭喜你,你已经可以开始linux的c语言编程之旅了。
当然,我们不会满足于这么简单的打印功能。下面就可以编写一个简单的迭代函数,
#include <stdio.h>
int iterate(int value)
{
if(1 == value)
return 1;
return iterate(value - 1) + value;
}
int main()
{
printf("%d\n", iterate(10));
return 1;
}
此时,同样我们需要重复上面的步骤:
1、输入gcc hello.c -o hello;
2、输入./hello。
当然此时如果一切OK的话,你就会看到屏幕会有55这个数的输出。本来1到10的数据之和就是55, 这说明我们的程序是正确的。
当然, 还会有一些朋友对程序的反汇编感兴趣,那么他需要两个步骤:
1、gcc hello.c -g -o hello;
2、objdump -S -d ./hello。
之所以在gcc编译的时候加上-g是为了添加调试信息,objdump中的-S选项是为了在显示汇编代码的时候同时显示原来的C语言源代码。
int iterate(int value)
{
8048374: 55 push %ebp
8048375: 89 e5 mov %esp,%ebp
8048377: 83 ec 08 sub $0x8,%esp
if(1 == value)
804837a: 83 7d 08 01 cmpl $0x1,0x8(%ebp)
804837e: 75 09 jne 8048389 <iterate+0x15>
return 1;
8048380: c7 45 fc 01 00 00 00 movl $0x1,0xfffffffc(%ebp)
8048387: eb 16 jmp 804839f <iterate+0x2b>
return iterate(value -1) + value;
8048389: 8b 45 08 mov 0x8(%ebp),%eax
804838c: 83 e8 01 sub $0x1,%eax
804838f: 89 04 24 mov %eax,(%esp)
8048392: e8 dd ff ff ff call 8048374 <iterate>
8048397: 8b 55 08 mov 0x8(%ebp),%edx
804839a: 01 c2 add %eax,%edx
804839c: 89 55 fc mov %edx,0xfffffffc(%ebp)
804839f: 8b 45 fc mov 0xfffffffc(%ebp),%eax
}
80483a2: c9 leave
80483a3: c3 ret
linux下的C语言开发(makefile编写)
对于程序设计员来说,makefile是我们绕不过去的一个坎。可能对于习惯Visual C++的用户来说,是否会编写makefile无所谓。毕竟工具本身已经帮我们做好了全部的编译流程。但是在Linux上面,一切变得不一样了,没有人会为你做这一切。编代码要靠你,测试要靠你,最后自动化编译设计也要靠你自己。想想看,如果你下载了一个开源软件,却因为自动化编译失败,那将会在很大程度上打击你学习代码的自信心了。所以,我的理解是这样的。我们要学会编写makefile,至少会编写最简单的makefile。
首先编写add.c文件,
#include "test.h"
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int main()
{
printf(" 2 + 3 = %d\n", add(2, 3));
printf(" 2 - 3 = %d\n", sub(2, 3));
return 1;
}
再编写sub.c文件,
#include "test.h"
int sub(int a, int b)
{
return a - b;
}
最后编写test.h文件,
#ifndef _TEST_H
#define _TEST_H
int add(int a, int b);
int sub(int a, int b);
#endif
那么,就是这三个简单的文件,应该怎么编写makefile呢?
test:
add.o sub.o
gcc -o test add.o sub.o
add.o:
add.c test.h
gcc -c add.c
sub.o:
sub.c test.h
gcc -c sub.c
clean:
rm -rf test
rm -rf *.o
linux下的C语言开发(gdb调试)
编写代码过程中少不了调试。在windows下面,我们有visual studio工具。在linux下面呢,实际上除了gdb工具之外,你没有别的选择。那么,怎么用gdb进行调试呢?我们可以一步一步来试试看。
#include <stdio.h>
int iterate(int value)
{undefined
if(1 == value)
return 1;
return iterate(value - 1) + value;
}
int main()
{undefined
printf("%d\n", iterate(10));
return 1;
}
既然需要调试,那么生成的可执行文件就需要包含调试的信息,这里应该怎么做呢?很简单,输入 gcc test.c -g -o test。输入命令之后,如果没有编译和链接方面的错误,你就可以看到 可执行文件test了。
调试的步骤基本如下所示,
(01) 首先,输入gdb test
(02) 进入到gdb的调试界面之后,输入list,即可看到test.c源文件
(03) 设置断点,输入 b main
(04) 启动test程序,输入run
(05) 程序在main开始的地方设置了断点,所以程序在printf处断住
(06) 这时候,可以单步跟踪。s单步可以进入到函数,而n单步则越过函数
(07) 如果希望从断点处继续运行程序,输入c
(08) 希望程序运行到函数结束,输入finish
(09) 查看断点信息,输入 info break
(10) 如果希望查看堆栈信息,输入bt
(11) 希望查看内存,输入 x/64xh + 内存地址
(12) 删除断点,则输入delete break + 断点序号
(13) 希望查看函数局部变量的数值,可以输入print + 变量名
(14)希望修改内存值,直接输入 print + *地址 = 数值
(15) 希望实时打印变量的数值,可以输入display + 变量名
(16) 查看函数的汇编代码,输入 disassemble + 函数名
(17) 退出调试输入quit即可
linux下的C语言开发(AT&T 汇编语言)
同样是x86的cpu,但是却可以用不同形式的汇编语言来表示。
在window上面我们使用的更多是intel格式的汇编语言,而在Linux系统上面使用的更多的常常是AT&T格式的汇编语言。那什么是AT&T格式的汇编代码呢?我们可以写一个试试看。
.data
message: .string "hello!\n"
length = . - message
.text
.global _start
_start:
movl $length, %edx
movl $message, %ecx
movl $1, %ebx
movl $4, %eax
int $0x80
movl $0, %ebx
movl $1, %eax
int $0x80
08048074 <_start>:
.text
.global _start
_start:
movl $length, %edx
8048074: ba 08 00 00 00 mov $0x8,%edx
movl $message, %ecx
8048079: b9 9c 90 04 08 mov $0x804909c,%ecx
movl $1, %ebx
804807e: bb 01 00 00 00 mov $0x1,%ebx
movl $4, %eax
8048083: b8 04 00 00 00 mov $0x4,%eax
int $0x80
8048088: cd 80 int $0x80
movl $0, %ebx
804808a: bb 00 00 00 00 mov $0x0,%ebx
movl $1, %eax
804808f: b8 01 00 00 00 mov $0x1,%eax
int $0x80
8048094: cd 80 int $0x80
ret
8048096: c3 ret
这是一个简单的汇编文件,我们可以分两步进行编译。首先,输入 as -gstabs -o hello.o hello.s, 接着输入ld -o hello hello.o即可。为了验证执行文件是否正确,可以输入./hello验证一下。
在as命令当中,由于我们使用了-gstabs选项,因此在hello执行文件中是包含调试信息的。所以,如果想单步调试的朋友可以输入gdb hello进行调试。
那么,hello执行文件反汇编的代码又是什么样的呢?我们可以输入objdump -S -d hello查看一下。
linux下的C语言开发(静态库)
在我们编写软件的过程当中,少不了需要使用别人的库函数。因为大家知道,软件是一个协作的工程。作为个人来讲,你不可能一个人完成所有的工作。另外,网络上一些优秀的开源库已经被业内广泛接受,我们也没有必要把时间浪费在这些重复的工作上面。
既然说到了库函数,那么一般来说库函数分为两种方式:静态库和动态库。两者的区别其实很小,静态库是必须要链接到执行文件中去的,而动态库是不需要链接到最后的执行文件中的。怎么理解呢?也就是说,对于最后的执行文件而言,你是否删除静态库无所谓。但是,一旦你删除了动态库,最后的执行文件就玩不转了。
今天我们讨论的问题是静态库。为了显示windows和linux创建静态库之间的差别,我们首先在windows上面利用Visual C++6.0创建一个静态库。源文件的代码很简单,
#include "test.h"
int add(int a, int b)
{
return a + b;
}
头文件代码也不难,
#ifndef _TEST_H
#define _TEST_H
int add(int a, int b);
#endif
如果你需要在windows上面创建一个静态库,那么你需要进行下面的操作,
(1)打开visual C++ 6.0工具,单击【File】-> 【New】->【Projects】
(2)选择【Win32 Static Library】,同时在【Project Name】写上项目名称,在【Location】选择项目保存地址
(3)单击【Ok】,继续单击【Finish】,再单击【Ok】,这样一个静态库工程就创建好了
(4)重新单击【File】->【New】->【Files】,选择【C++ Source Files】,
(5)选中【Add to pproject】,将源文件加入到刚才创建的工程中去,在File中输入文件名+.c后缀
(6)重复4、5的操作,加入一个文件名+.h头文件
(7)分别在头文件和源文件中输入上面的代码,单击F7按钮,即可在Debug目录中生成*.lib静态库文件
那么,在linux下面应该怎么运行呢?其实很简单,两条命令解决,
(1)首先生成*.o文件,输入gcc -c test.c -o test.o
(2)利用ar命令生成静态库,输入ar rc libtest.a test.o
此时如果还有一个hello.c文件使用到了这个静态库,比如说 ,
#include <stdio.h>
#include "test.h"
int main()
{
printf("%d\n", add(2, 3));
return 1;
}
其实也很简单,输入一个简单的命令就可以生成执行文件了,
(1)首先输入gcc hello.c -o hello ./libtest.a
(2)输入./hello,验证生成的执行文件是否正确
(3)朋友们可以删除libtest.a文件,重新输入./hello,验证执行文件是否可以正常运行
linux下的C语言开发(动态库)
动态链接库不是linux独有的特性,在windows下面也存在这样的特性。一般来说,windows下面的动态连接库是以.dll作为结尾的,而linux下面的动态连接库是以.so结尾的。和静态链接库相比,动态连接库可以共享内存资源,这样可以减少内存消耗。另外,动态连接是需要经过操作系统加载器的帮助才能被普通执行文件发现的,所以动态连接库可以减少链接的次数。有了这个特点,我们就不难发现为什么很多软件的补丁其实都是以动态库发布的。
那么,在Linux上动态库是怎么生成的呢?
#include "test.h"
int add(int a, int b)
{
return a + b;
}
头文件格式,
#ifndef _TEST_H
#define _TEST_H
int add(int a, int b);
#endif
此时如果我们想要生成动态库,要做的工作其实非常简单,输入gcc -shared -fPIC -o libtest.so test.c即可。回车后输入ls,我们就可以发现当前目录下面出现了libtest.so文件。
#include <stdio.h>
#include "test.h"
int main()
{
printf("%d\n", add(2, 3));
return 1;
}
在上面的代码当中,我们发现使用到了add函数,那么此时如何才能生成一个执行文件呢?也很简单,输入gcc hello.c -o hello ./libtest.so。然后输入./hello,此时可以验证一下执行文件运行是否正确。在编写静态库的时候,我说过静态库是汇编链接到执行文件当中的,而动态库不会。朋友们可以做个小实验,删除libtest.so,然后输入./hello。此时大家可以看看系统有没有错误返回?
这个时候,有的朋友就会问了,那在windows下面dll应该怎么编写呢?其实也不难,只要在test.h上面稍作改变即可。其他的步骤和静态库的操作是基本类似的。
#ifndef _TEST_H
#define _TEST_H
#ifdef USR_DLL
#define DLL_API _declspec(dllexport)
#else
#define DLL_API _declspec(dllimport)
#endif
DLL_API int add(int a, int b);
#endif
linux下的C语言开发(定时器)
定时器是我们需要经常处理的一种资源。那linux下面的定时器又是怎么一回事呢?其实,在linux里面有一种进程中信息传递的方法,那就是信号。这里的定时器就相当于系统每隔一段时间给进程发一个定时信号,我们所要做的就是定义一个信号处理函数。
#include <stdio.h>
#include <time.h>
#include <sys/time.h>
#include <stdlib.h>
#include <signal.h>
static int count = 0;
static struct itimerval oldtv;
void set_timer()
{
struct itimerval itv;
itv.it_interval.tv_sec = 1;
itv.it_interval.tv_usec = 0;
itv.it_value.tv_sec = 1;
itv.it_value.tv_usec = 0;
setitimer(ITIMER_REAL, &itv, &oldtv);
}
void signal_handler(int m)
{
count ++;
printf("%d\n", count);
}
int main()
{
signal(SIGALRM, signal_handler);
set_timer();
while(count < 10000);
exit(0);
return 1;
}
linux下的C语言开发(自动编译工具)
在Linux下面,编写makefile是一件辛苦的事情。因此,为了减轻程序员编写makefile的负担,人们发明了autoconf和automake这两个工具,可以很好地帮我们解决这个问题。
我们可以通过一个简单的示例来说明如何使用配置工具。
(1)首先,编写源文件hello.c。
#include <stdio.h>
int main(int argc, char** argv[])
{
printf("hello, world!\n");
return 1;
}
(2)接下来,我们需要创建一个Makefile.am,同时编写上脚本。
SUBDIRS=
bin_PROGRAMS=hello
hello_SOURCES=hello.c
(3)直接输入autoscan,生成文件configure.scan,再改名为configure.in。修改脚本AC_INIT(FULL-PACKAGE-NAME, VERSION, BUG-REPORT-ADDRESS)为AC_INIT(hello, 1.0, feixiaoxing@163.com)同时,在AC_CONFIG_HEADER([config.h])后面添加AM_INIT_AUTOMAKE(hello, 0.1)
(4)依次输入aclocal命令、autoheader命令
(5)创建4个文件,分别为README、NEWS、AUTHORS和ChangeLog
(6)依次输入automake -a、autoconf命令
(7)输入./configure,生成最终的Makefile
(8)如果需要编译,输入make;如果需要安装, 输入make install;如果需要发布软件包,输入make dist
linux下的C语言开发(进程创建)
在Linux下面,创建进程是一件十分有意思的事情。我们都知道,进程是操作系统下面享有资源的基本单位。那么,在Linux下面应该怎么创建进程呢?其实非常简单,一个fork函数就可以搞定了。但是,我们需要清楚的是子进程与父进程之间除了代码是共享的之外,堆栈数据和全局数据均是独立的。
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
pid_t pid;
if(-1 == (pid = fork())) {
printf("Error happened in fork function!\n");
return 0;
}
if(0 == pid) {
printf("This is child process: %d\n", getpid());
} else {
printf("This is parent process: %d\n", getpid());
}
return 0;
}
linux下的C语言开发(进程等待)
所谓进程等待,其实很简单。前面我们说过可以用fork创建子进程,那么这里我们就可以使用wait函数让父进程等待子进程运行结束后才开始运行。注意,为了证明父进程确实是等待子进程运行结束后才继续运行的,我们使用了sleep函数。但是,在linux下面,sleep函数的参数是秒,而windows下面sleep的函数参数是毫秒。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char* argv[])
{
pid_t pid;
pid = fork();
if(0 == pid) {
printf("This is child process, %d\n", getpid());
sleep(5);
} else {
wait(NULL);
printf("This is parent process, %d\n", getpid());
}
return 1;
}
下面,我们需要做的就是两步,首先输入gcc fork.c -o fork, 然后输入./fork,就会在console下面获得这样的结果。
[root@localhost fork]# ./fork
This is child process, 2135
This is parent process, 2134
linux下的C语言开发(信号处理)
信号处理是linux程序的一个特色。用信号处理来模拟操作系统的中断功能,对于我们这些系统程序员来说是最好的一个选择了。要想使用信号处理功能,你要做的就是填写一个信号处理函数即可。一旦进程有待处理的信号处理,那么进程就会立即进行处理。
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
int value = 0;
void func(int sig)
{
printf("I get a signal!\n");
value = 1;
}
int main()
{
signal(SIGINT, func);
while(0 == value)
sleep(1);
return 0;
}
为了显示linux对signal的处理流程,我们需要进行两个步骤。
第一,输入gcc sig.c -o sig, 然后输入./sig即可;
第二则重启一个console窗口,输入ps -aux | grep sig, 在获取sig的pid之后然后输入kill -INT 2082, 我们即可得到如下的输出。
[root@localhost fork]#./sig
I get a signal!
[root@localhost fork]#
linux下的C语言开发(管道通信)
Linux系统本身为进程间通信提供了很多的方式,比如说管道、共享内存、socket通信等。管道的使用十分简单,在创建了匿名管道之后,我们只需要从一个管道发送数据,再从另外一个管道接受数据即可。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
int pipe_default[2];
int main()
{
pid_t pid;
char buffer[32];
memset(buffer, 0, 32);
if(pipe(pipe_default) < 0) {
printf("Failed to create pipe!\n");
return 0;
}
if(0 == (pid = fork())) {
close(pipe_default[1]);
sleep(5);
if(read(pipe_default[0], buffer, 32) > 0) {
printf("Receive data from server, %s!\n", buffer);
}
close(pipe_default[0]);
} else {
close(pipe_default[0]);
if(-1 != write(pipe_default[1], "hello", strlen("hello"))) {
printf("Send data to client, hello!\n");
}
close(pipe_default[1]);
waitpid(pid, NULL, 0);
}
return 1;
}
下面我们就可以开始编译运行了,老规矩分成两步骤进行:
(1)输入gcc pipe.c -o pipe;
(2)然后输入./pipe,过一会儿你就可以看到下面的打印了。
[test@localhost pipe]$ ./pipe
Send data to client, hello!
Receive data from server, hello!
linux下的C语言开发(多线程编程)
多线程和多进程还是有很多区别的。其中之一就是,多进程是linux内核本身所支持的,而多线程则需要相应的动态库进行支持。对于进程而言,数据之间都是相互隔离的,而多线程则不同,不同的线程除了堆栈空间之外所有的数据都是共享的。说了这么多,我们还是自己编写一个多线程程序看看结果究竟是怎么样的。
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
void func_1(void* args)
{
while(1) {
sleep(1);
printf("this is func_1!\n");
}
}
void func_2(void* args)
{
while(1) {
sleep(2);
printf("this is func_2!\n");
}
}
int main()
{
pthread_t pid1, pid2;
if(pthread_create(&pid1, NULL, func_1, NULL)) {
return -1;
}
if(pthread_create(&pid2, NULL, func_2, NULL)) {
return -1;
}
while(1) {
sleep(3);
}
return 0;
}
和我们以前编写的程序有所不同,多线程代码需要这样编译,输入gcc thread.c -o thread -lpthread,编译之后你就可以看到thread可执行文件,输入./thread即可。
[test@localhost Desktop]$ ./thread
this is func_1!
this is func_2!
this is func_1!
this is func_1!
this is func_2!
this is func_1!
this is func_1!
this is func_2!
this is func_1!
this is func_1!
linux下的C语言开发(线程等待)
和多进程一样,多线程也有自己的等待函数。这个等待函数就是pthread_join函数。那么这个函数有什么用呢?我们其实可以用它来等待线程运行结束。
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
void func(void* args)
{
sleep(2);
printf("this is func!\n");
}
int main()
{
pthread_t pid;
if(pthread_create(&pid, NULL, func, NULL)) {
return -1;
}
pthread_join(pid, NULL);
printf("this is end of main!\n");
return 0;
}
编写wait.c文件结束之后,我们就可以开始编译了。首先你需要输入gcc wait.c -o wait -lpthread,编译之后你就可以看到wait可执行文件,输入./wait即可。
[test@localhost thread]$ ./thread
this is func!
this is end of main!
linux下的C语言开发(线程互斥)
对于编写多线程的朋友来说,线程互斥是少不了的。在linux下面,编写多线程常用的工具其实是pthread_mutex_t。本质上来说,它和Windows下面的mutex其实是一样的,差别几乎是没有。希望对线程互斥进行详细了解的朋友可以看这里。
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
static int value = 0;
pthread_mutex_t mutex;
void func(void* args)
{
while(1) {
pthread_mutex_lock(&mutex);
sleep(1);
value ++;
printf("value = %d!\n", value);
pthread_mutex_unlock(&mutex);
}
}
int main()
{
pthread_t pid1, pid2;
pthread_mutex_init(&mutex, NULL);
if(pthread_create(&pid1, NULL, func, NULL)) {
return -1;
}
if(pthread_create(&pid2, NULL, func, NULL)) {
return -1;
}
while(1)
sleep(0);
return 0;
}
编写mutex.c文件结束之后,我们就可以开始编译了。首先你需要输入gcc mutex.c -o mutex -lpthread,编译之后你就可以看到mutex可执行文件,输入./mutex即可。
[test@localhost thread]$ ./mutex
value = 1!
value = 2!
value = 3!
value = 4!
value = 5!
value = 6!
linux下的C语言开发(网络编程)
不管在Windows平台下面还是在Linux平台下面,网络编程都是少不了的。在互联网发达的今天,我们的生活基本上已经离不开网络了。我们可以用网络干很多的事情,比如说IM聊天、FTP下载、电子银行、网络购物、在线游戏、电子邮件的收发等等。所以说,对于一个软件的开发者来说,如果说他不会进行网络程序的开发,那真是难以想象的。
在开始介绍网络编程的方法之前,我们可以回忆一下计算机网络的相关知识。目前为止,我们使用的最多网络协议还是tcp/ip网络。通常来说,我们习惯上称为tcp/ip协议栈。至于协议栈分成几层,有两种说法。一种是五层,一种是七层,我个人本身也比较倾向于五层的划分方法。大家可以通过下面的图看看协议栈是怎么划分的。
5、应用层
4、传输层
3、网络层
2、数据链路层
1、物理层
网络的不同层次实现网络的不同功能。物理层主要实现报文的成帧处理;数据链路层完成对报文的优先级的管理,同时实现二层转发和流量控制;网络层实现路由和转发的功能,一方面它需要实现对报文的fragment处理,另外一方面它还需要对路由信息进行处理和保存;传输层实现报文的发送和接受,它利用计数、时序、定时器、重发等机制实现对报文的准确发送,当然这都是tcp的发送机制,而udp一般是不保证报文正确发送和接收的;应用层就是根据传输层的端口信息调用不同的程序来处理传输的内容,端口8080是http报文,端口21是ftp报文等等。上面的逻辑稍显复杂,朋友们可以这么理解,
物理层关心的是如何把电气信号变成一段报文;数据链路层关心的是mac地址、vlan、优先级等;网络层关心的是ip地址,下一跳ip;传输层关心的是端口资源;应用层关心的是报文组装、解析、渲染、存储、执行等等。
目前关于tcp/ip完整协议栈的代码很多,其中我认为写得比较好的还是linux内核/net/ipv4下面的代码。如果朋友们对ipv6的代码感兴趣,也可以看看/net/ipv6的代码。档案如果朋友们对整个协议栈的代码结构理解得不是很清楚,可以参考《linux网络分析与开发》这本书。
当然,作为应用层,我们的其实考虑的不用这么复杂。对于网络程序编写人员来讲,所有网络的资源只要和一个socket关联在一起就可以了。当然在socket可用之前,我们需要为它配置端口信息和ip地址。配置完了之后,我们就可以慢慢等待报文的收发了。所以一般来说,作为服务器端口的处理流程是这样的,
a) 创建socket
b) 绑定socket到特定的ip地址
c) 对socket进行侦听处理
d) 接受socket,表明有客户端和服务器连接
e) 和客户端循环收发报文
f) 关闭socket
作为服务器程序而言,它要对特定的端口进行绑定和侦听处理,这样稍显复杂。但是如果是编写客户端的程序,一切的一切就变得非常简单了,
a) 创建socket
b) 链接服务器端地址
c) 和服务器端的socket收发报文
上面只是对网络编程做了一个基本的介绍,但是好多的东西还是没有涉及到,比如说:
(1) 什么时候该使用udp,什么时候该使用tcp?
(2) 如何把多线程和网络编程联系在一起?
(3) 如何把多进程和网络编程联系在一起?
(4) 如何利用select函数、epoll_create机制、非阻塞函数提高socket的并发处理效率?
(5) linux内核是怎么实现tcp/ip协议的?
(6) 我们自己是否也可以实现协议的处理流程等等?
参考文章:https://blog.csdn.net/weixin_40756041/article/details/88112872